가격 예측 29 2025 년 3 월")




































Flow 소식
-
2025
03 / 29는 3 월에 첫 번째 롤아웃을 준비하여 새로운 복구 메커니즘으로 체인을 업그레이드합니다.")
 교환 흐름 데이터는 강력한 집회가 앞서있을 수 있음을 시사합니다.")



은 상당한 가격 랠리 직전에있을 수 있습니다.")
 Exchange 거래 자금 (ETF)은 10 일 연속 순 유입 자금")
-
2025
03 / 28 -
- {{val.name}}
- {{val.createtime}}
- {{val.seo_description}}

 가격이 상승하는 동안 다른 모든 것이 다운되는 이유는 다음과 같습니다.")
커뮤니티 피드
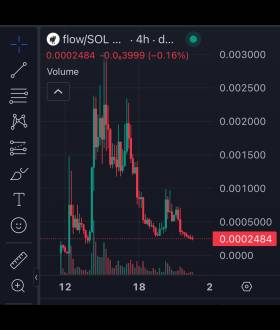
- 그리고상은 너무…. $flow
-

- Twitter 원천
- Casey Ford Alexander 2025-03-23 02:16:20
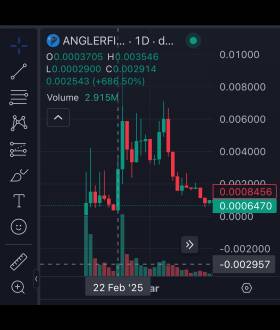
그들은 #anglerfish이 $ 10m로 달리기 전에 $ 290K로 떨어 졌다는 것을 잊어 버렸습니다. 그러나 요즘 차트를 공부하는 사람은 누가 DCAS 및/또는 좋은 진입 및 홀드를 기다리는 사람, 누가 초기에 상위를 팔고, 이익을 가져 와서 바닥에서 다시 구매합니까? 그들은 단지 Th와 함께 가야합니다 e $flow
그들은 단지 Th와 함께 가야합니다 e $flow 

- $flow 다음 큰 밈입니다! 벌써 4 천만 건으로 거쳤다 !!! Mindshare는 미쳤다 !!!! 거룩한 젠장 Dogshit“Memecoin”이 무엇인지
 나이지리아 거지들이 이것에 대해 잊어 버리기 위해 20 달러짜리 경품을 운영
나이지리아 거지들이 이것에 대해 잊어 버리기 위해 20 달러짜리 경품을 운영 -
- 안녕하세요, 트렌치의 Shadow Shadem은 여전히 잡고 있습니까? $flow 토큰? 당신은 37 분 동안 그것에 대해 트윗하지 않았으므로 내가 팔아야하는지 궁금합니다. 감사해요
-
-
- Twitter 원천
- {{val.author }} {{val.createtime }}