Aventus 소식
-
2025
02 / 10 -
2025
02 / 08 -
2025
01 / 26
- VideoLLaMA3: 모든 해상도 비전 토큰화 및 Differential Frame Pruner를 갖춘 다중 모드 모델을 위한 비전 중심 프레임워크
- 2025-01-26 14:00:00
- 다중 모드 지능의 발전은 이미지와 비디오를 처리하고 이해하는 데 달려 있습니다. 이미지는 객체, 텍스트, 공간 관계 등 세부 정보에 관한 정보를 제공하여 정적 장면을 드러낼 수 있습니다. 그러나 이는 극도로 어려운 대가를 치르게 됩니다. 비디오 이해에는 여러 작업 중에서 시간 경과에 따른 변화를 추적하는 동시에 프레임 전반에 걸쳐 일관성을 보장하는 작업이 포함되며 동적 콘텐츠 관리 및 시간적 관계가 필요합니다. 비디오 텍스트 데이터세트의 수집과 주석이 이미지-텍스트 데이터세트에 비해 상대적으로 어렵기 때문에 이러한 작업은 더욱 어려워집니다.
-
2024
10 / 23 -
2024
10 / 22 -
- {{val.name}}
- {{val.createtime}}
- {{val.seo_description}}



커뮤니티 피드
-

- Twitter 원천
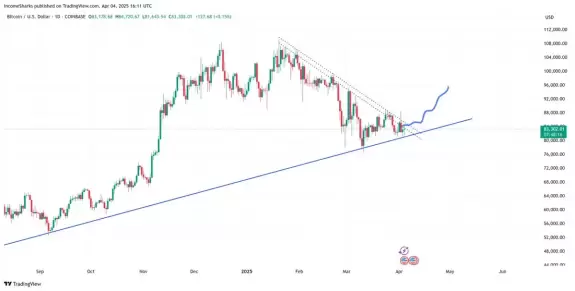
- IncomeSharks 2025-04-05 00:14:54
-
- Twitter 원천
- Farmercist👨🌾 2025-04-05 00:07:03
-

- Twitter 원천
- Travladd Crypto 𐤊 2025-04-05 00:00:01
-

- Twitter 원천
- Gokhan Gark 2025-04-04 21:43:36
-

- Twitter 원천
- ALTERFIND🔍 2025-04-04 20:15:28
-

- Twitter 원천
- Altcoin Daily 2025-04-04 20:02:00
Vechain의 중요성은 충분히 이야기되지 않았습니다. $VET -
- Twitter 원천
- {{val.author }} {{val.createtime }}